
数据准备
更新时间:2023-02-09
用户设置
- 在代码最开始处设置您在官网获取到的ak和sk
import wenxin_api
wenxin_api.ak = "your ak"
wenxin_api.sk = "your sk"准备训练数据
请确保您用于训练的图片数据已获得充分的授权,且不存在任何使用风险!更多详情请仔细阅读《服务条款》的相关内容。
-
准备匹配的图片和文本
-
用尽可能详细、多样的语言描述每张图片。
a. 在描述需要学习的主体时,可以使用“主体的类别”+“主体的名字”的形式。如下图需要学习的狗、木质壶的名字分别表示为“[d]"、“[p]”,则图片对应的描述为“一只狗[d]的照片”、“一个木质壶[p]的照片”。Tips:名字用越特殊、少见的字符组合表示,效果越好,如小狗名字为“[d]”的效果,比表示为“旺财”的效果好。
b. 在描述需要学习的风格时,可以使用“风格的名字”+“风格”的形式。如下图需要学习的风格表示为“spst”,则图片对应的描述为“spst风格画的沙滩和大海"。
c. 微调模型后生成图片时,文本中使用主体或风格的名字,加上其他描述,可以生成指定主体或风格在各种场景中的图片,例如“狗[d]抱着一个木质壶[p]哭,照片”、“spst风格画的一只狗”。
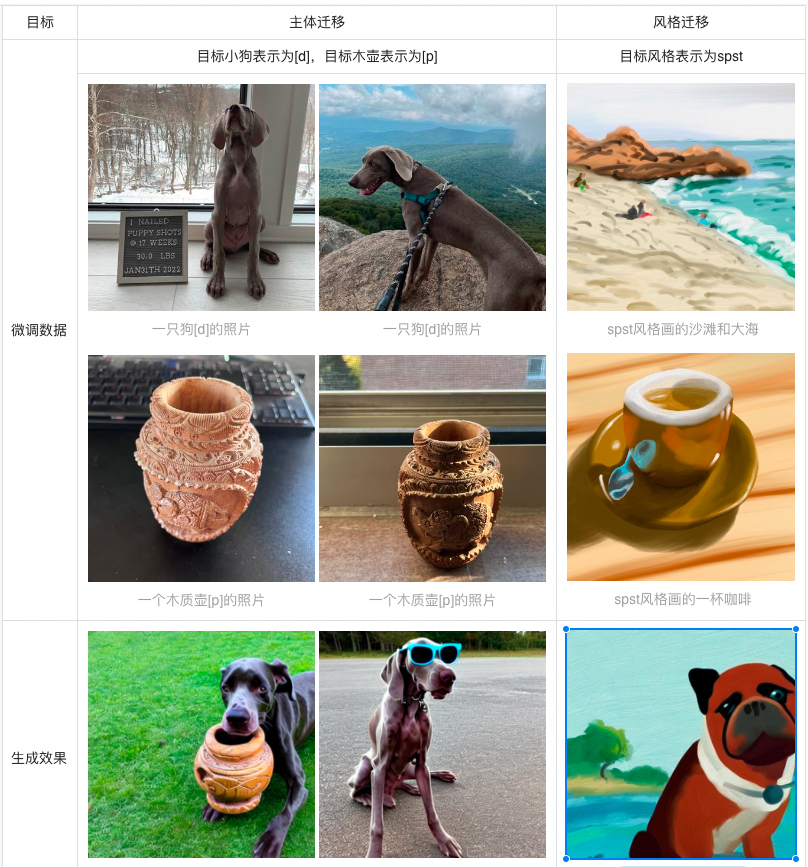
上述生成效果图片对应的prompt分别为:(狗[d]抱着一个木质壶[p]哭,照片、一只狗[d]戴墨镜的照片、spst风格画的一只狗).注:所有用于训练的目标主体和风格的图片来源:https://www.cs.cmu.edu/~custom-diffusion/;生成效果为ERNIE-ViLG模型精调后的实际生成图片。
- 建议将图片裁剪成方形。如果上传的图片不是方形,预处理时会自动裁剪成方形。
- 为保证生成图片的清晰度,建议训练图片的分辨率在512*512及以上。
- 上传的照片总数在8-10000张之间。
-
-
提高微调成功率和效果的方法(强烈建议使用)
- 用ERNIE-ViLG生成辅助图片
a. 当训练数据小于10张时,建议用线上的ERNIE-ViLG接口生成辅助图片,可以提高精调的效果。
b. 对于训练数据中的描述文本,去掉目标主体或风格的名字后,用ERNIE-ViLG页面进行生成。如训练数据包含“一只狗[d]的照片”,则用ERNIE-ViLG(https://wenxin.baidu.com/ernie-vilg)解锁更多风格功能(申请即可,大约四个小时后生效,解锁后没有风格选项,即可生成原始输入文本的结果)后生成同等数量的“一只狗的照片”,效果如下:
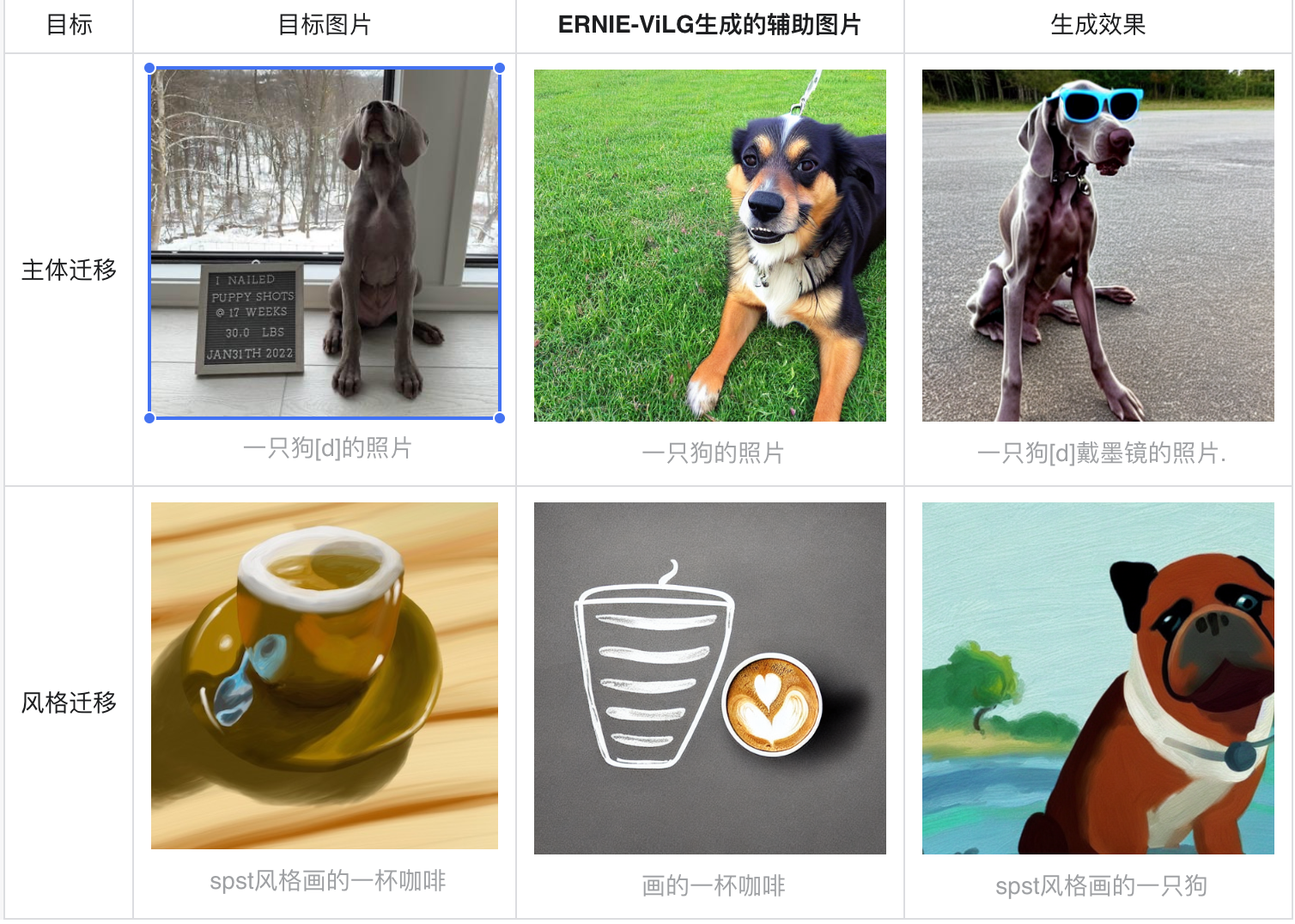
- 需要学习的同一主体的不同图片中的背景越丰富越好,需要学习的同一风格的不同图片中的内容越丰富越好,更容易让模型理解需要学到的东西。
a. 上传同一只小狗的8张照片,背景分别为家里、草地、大山,微调后的模型可以生成各种背景下的小狗。 (建议)
b. 上传同一只小狗的8张照片,背景都是草地,微调后的模型可能只会生成草地上的小狗。(不建议) - 同一主体或风格的训练图片越多越好,角度越多越好
a. 上传同一只小狗的正面、侧面、背面、半身、全身照片(建议)
b. 只上传一张小狗的正面半身照片(不建议) - 需要学习多个主体或风格时
a.不同的主体精调使用不同的模型,如小猫的照片精调一个模型,小狗的照片精调另一个模型,缺点是小猫和小狗无法出现在同一张照片中.(建议) b.当每个主体对应的图片数量较少时,尽量用完全不同类别的主体微调同一个模型,如用小狗的4张照片和水壶的4张照片微调同一个模型(这里小狗和水壶类别差距大),并生成小狗和水壶同时出现的照片.(建议) c.一共5个主体,都是动物,每个只有一张图片,用于精调同个模型(这里五个物体,由于都是动物,类间差别小,可能导致模型学习不够好),并试图生成5个主体同时出现的图片(不建议)
- 用ERNIE-ViLG生成辅助图片
-
上传格式
- 将所有图片描述的文本置于prompt.txt中,置于local_file_path根目录下。
- 在根目录下创建image文件夹,将每个prompt对应的图片置于以prompt.txt中的序号(从0开始)命名的文件夹下,可接受的图片格式包括jpg,png,jpeg,JPEG,JPG。
- 严格遵循如下的数据结构,整个结构在data命名的文件夹下面,data下面是train_data命名的文件夹,train_data下面包含image命名的文件夹和prompt命名的文件夹,image文件夹下面按照0、1、2索引构建(和prompt.txt里面的问本一一对应),每个索引文件夹下面的图片命名不做要求(不要以"."开头即可),例如不要以:".rose.jpg"这种命名即可,其他不做要求.
data
└── train_data
├── image
│ ├── 0
│ │ ├── 00000_0.jpg
│ │ └── 00000_1.jpg
│ ├── 1
│ │ ├── 00000_0.jpg
│ │ └── 00000_1.jpg
│ └── 2
│ ├── 00000_0.jpg
│ └── 00000_1.jpg
└── prompt
└── prompt.txt
- 将整个data目录打包成tar包,然后local_file_path改为tar包的么路径即可.
tar cvf xx.tar data - 参数设置参考:
注: epoch = (step * batch_size) / total_data
| 参数 | 类型 | 取值范围 |
|---|---|---|
| batch_size | int | 1<=bs<=8 |
| learning_rate | float | learning_rate>0 |
| step | int | step>0 |
取值建议:
- 训练集共8张图片:lr=1e-5,step=200,batch_size=4
- 训练集共1000张图片:lr=1e-5,step=1000,batch_size=8
创建数据集
from wenxin_api import Dataset
from wenxin_api.const import TYPE_TEXT_TO_IMAGE
local_file_path = "your file"
dataset = Dataset.create(local_file_path = local_file_path,need_check=False,api_type=TYPE_TEXT_TO_IMAGE)查看数据集
from wenxin_api import Dataset
from wenxin_api.const import TYPE_TEXT_TO_IMAGE
#查看所有数据集
datasets = Dataset.list(api_type=TYPE_TEXT_TO_IMAGE)
print(datasets)
# 查看指定数据集
data_id = "your dataset id"
dataset = Dataset.retrieve(data_id=data_id, api_type=TYPE_TEXT_TO_IMAGE)
print(dataset)- 数据集返回格式
{
"id":88,
"name":"test5",
"url":"http://bj.bcebos.com/api-platform-wenxin/tuning/2EEE631CDBFE7FB2DA78720680055CAC",
"md5":"2eee631cdbfe7fb2da78720680055cac",
"type":"data"
}删除数据集
from wenxin_api import Dataset
dataset_id="your dataset id"
Dataset.delete(data_id=dataset_id, api_type=TYPE_TEXT_TO_IMAGE)